Project Summary:
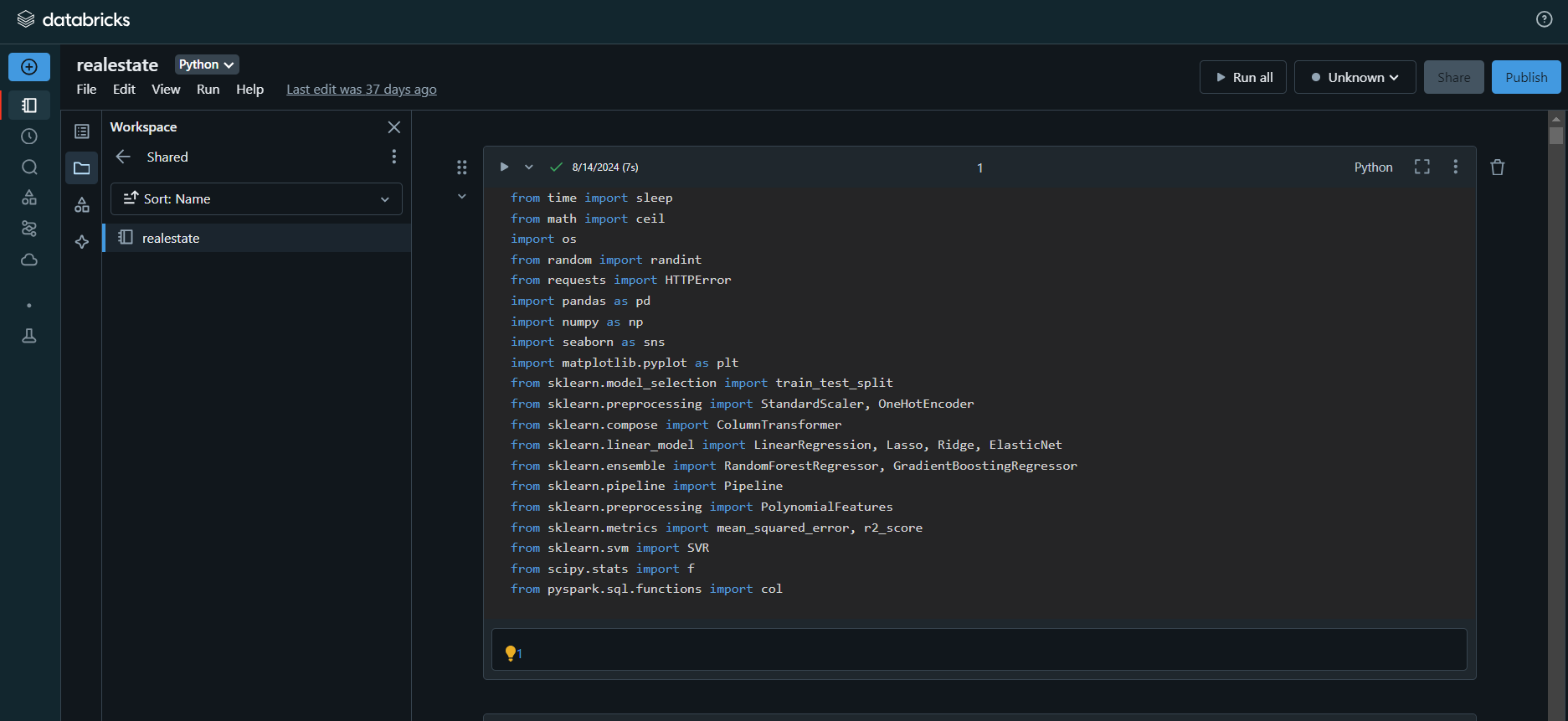
This project focuses on predicting real estate prices in the
USA using various regression models. The dataset, sourced
from Kaggle and enriched with additional neighborhood data,
was analyzed and preprocessed using Python and Databricks.
The goal was to develop predictive models that estimate
property prices based on features like property size,
location, number of rooms, and other relevant variables.
Several regression techniques, including Linear, Lasso,
Ridge, Polynomial, ElasticNet, RandomForest, and
GradientBoosting, were implemented and evaluated. The
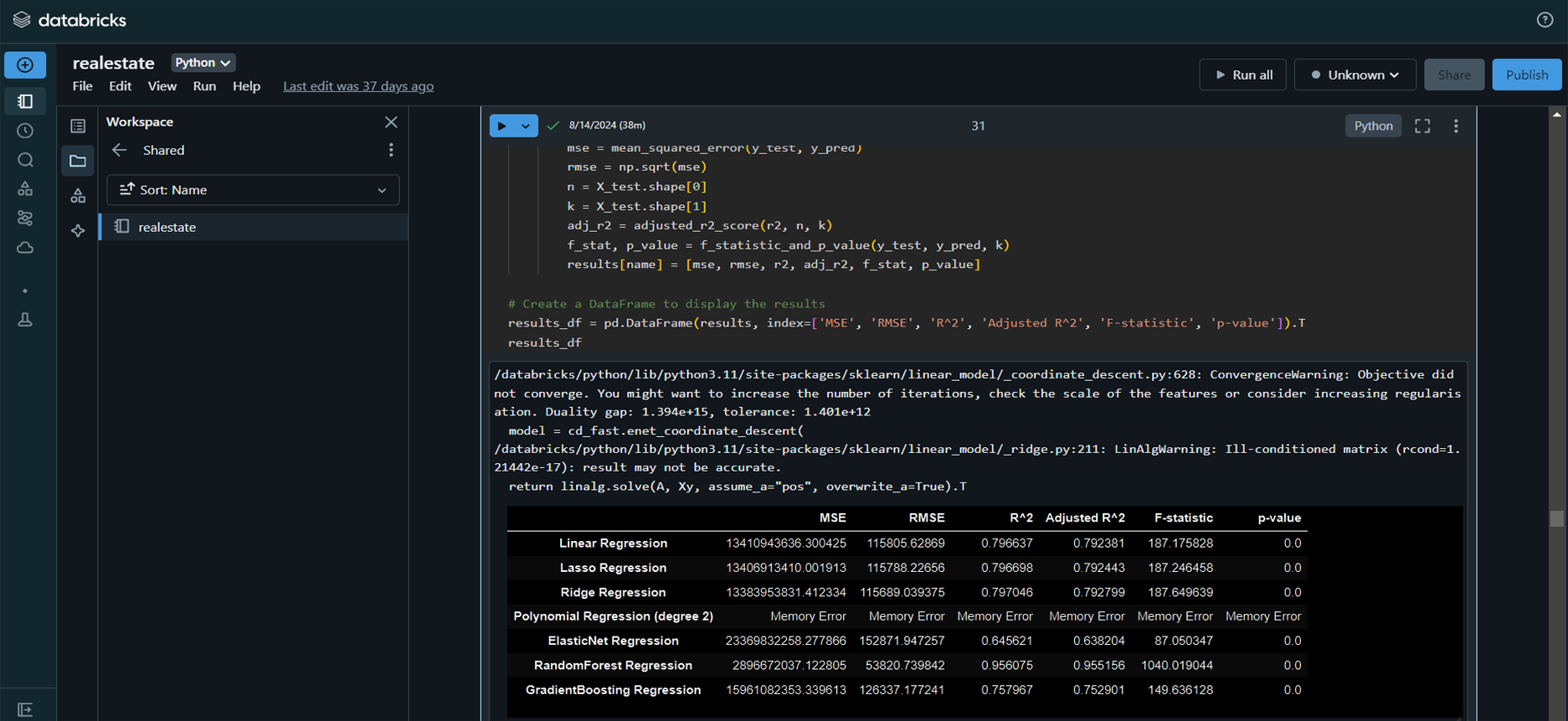
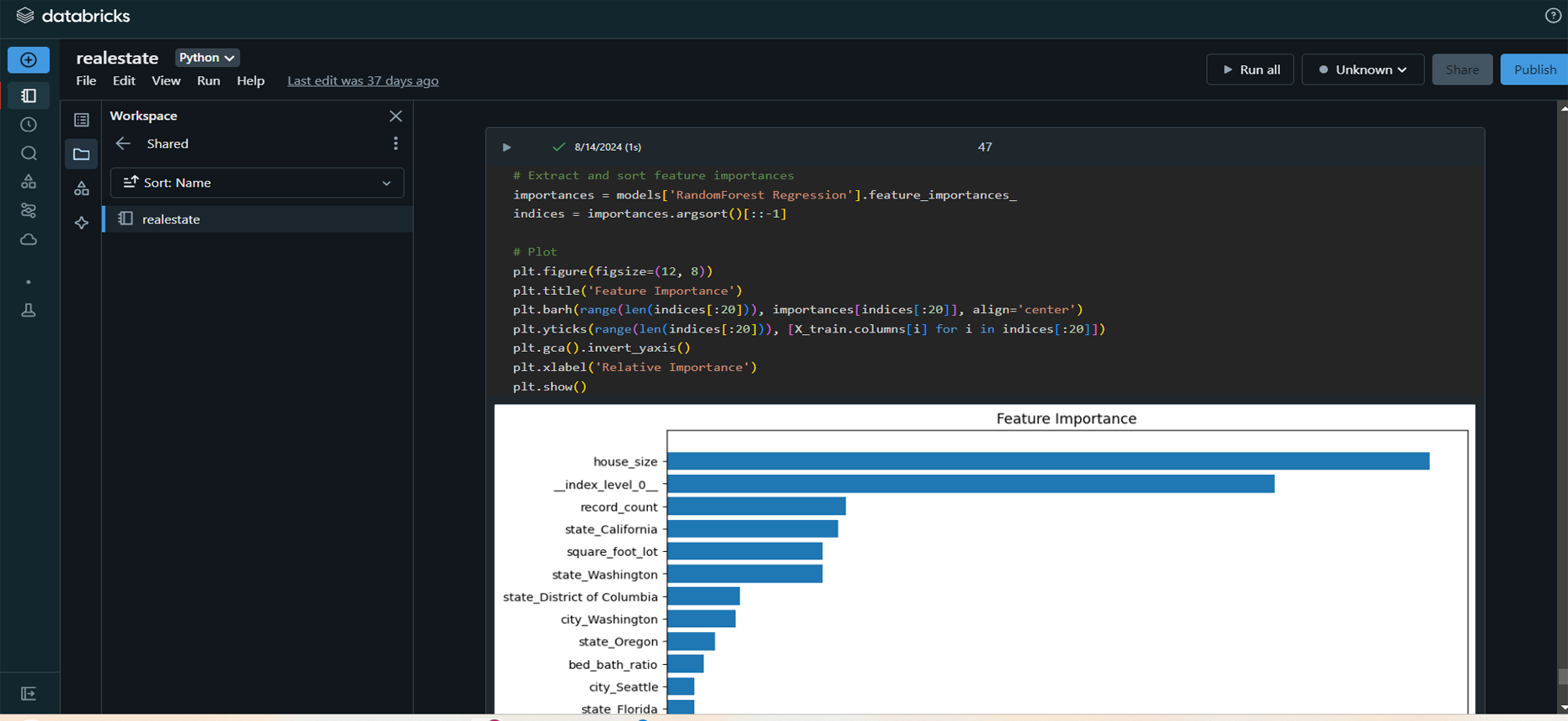
RandomForest Regression model emerged as the best performer,
providing the most accurate price predictions.
Read More
Technologies:
-
Python (Pandas, Scikit-learn, NumPy, Matplotlib,
Seaborn):
Data analysis, modeling, and visualization.
-
Databricks: For large-scale data
processing and model evaluation.
-
Azure Blob Storage: Data storage for
real estate and neighborhood data.
-
Regression Models: Linear, Lasso,
Ridge, Polynomial, ElasticNet, RandomForest,
GradientBoosting.
Contributions:
-
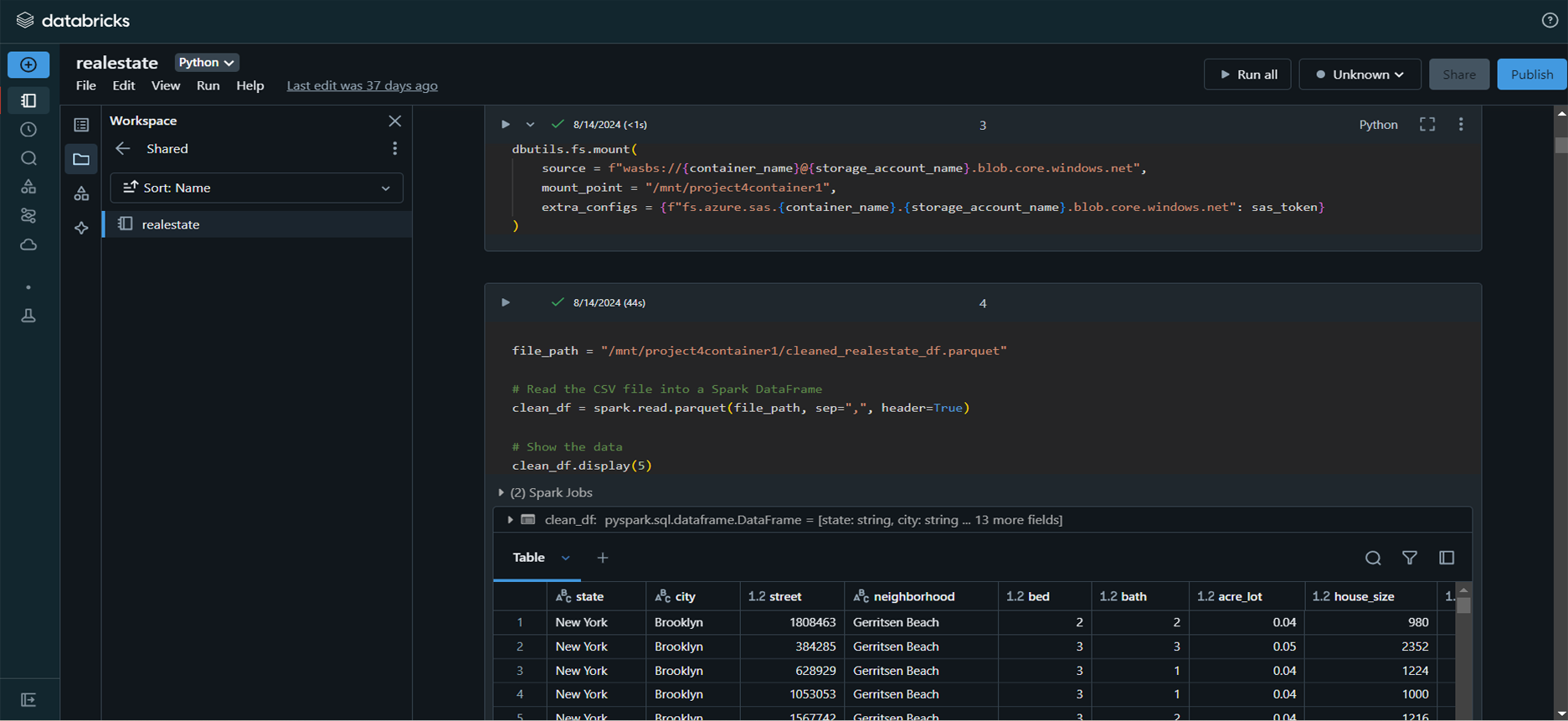
Data Integration and Access: Integrated
real estate data from Azure Blob Storage into Databricks
for large-scale analysis.
-
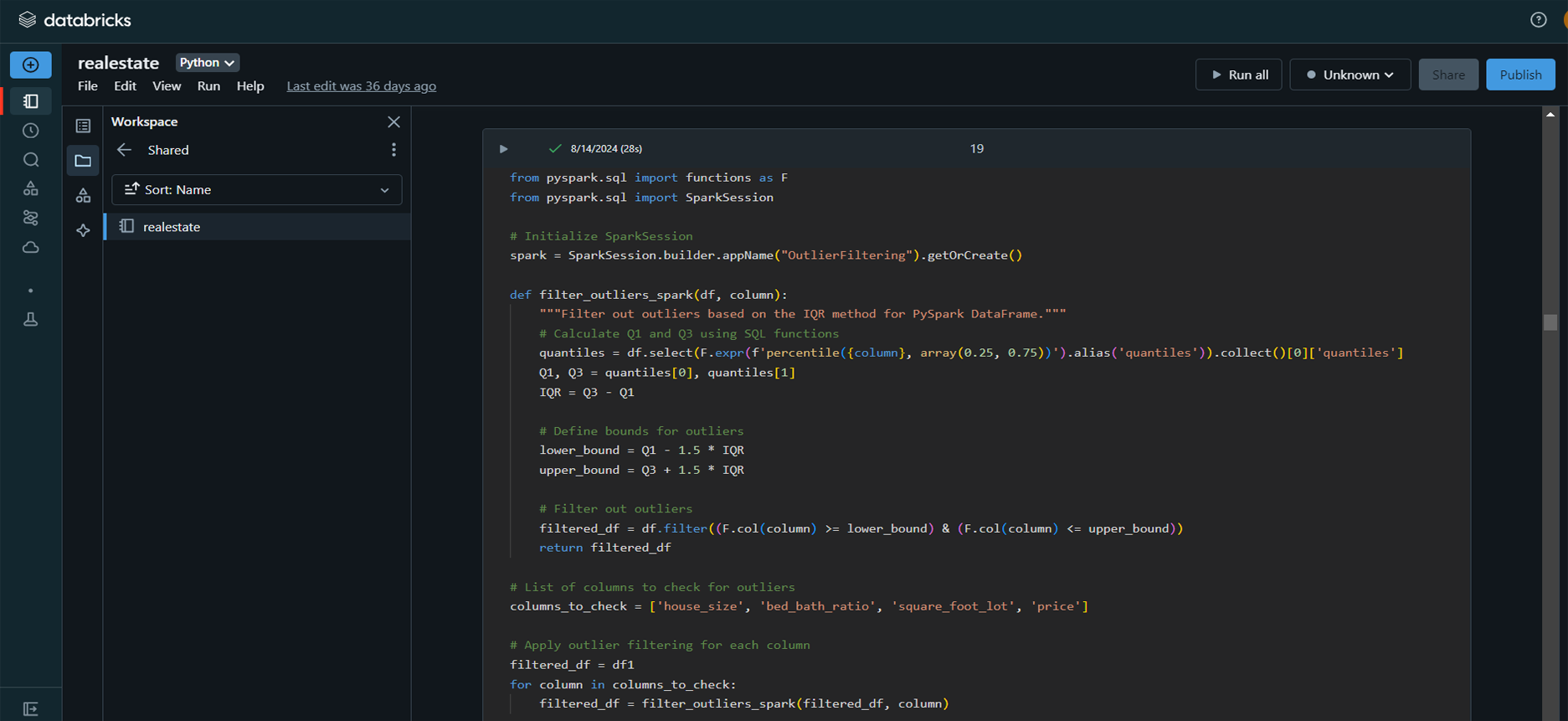
Data Preprocessing: Cleaned, merged,
and prepared datasets for modeling, including converting
acre to square feet and encoding categorical variables
like neighborhood, city, and state.
-
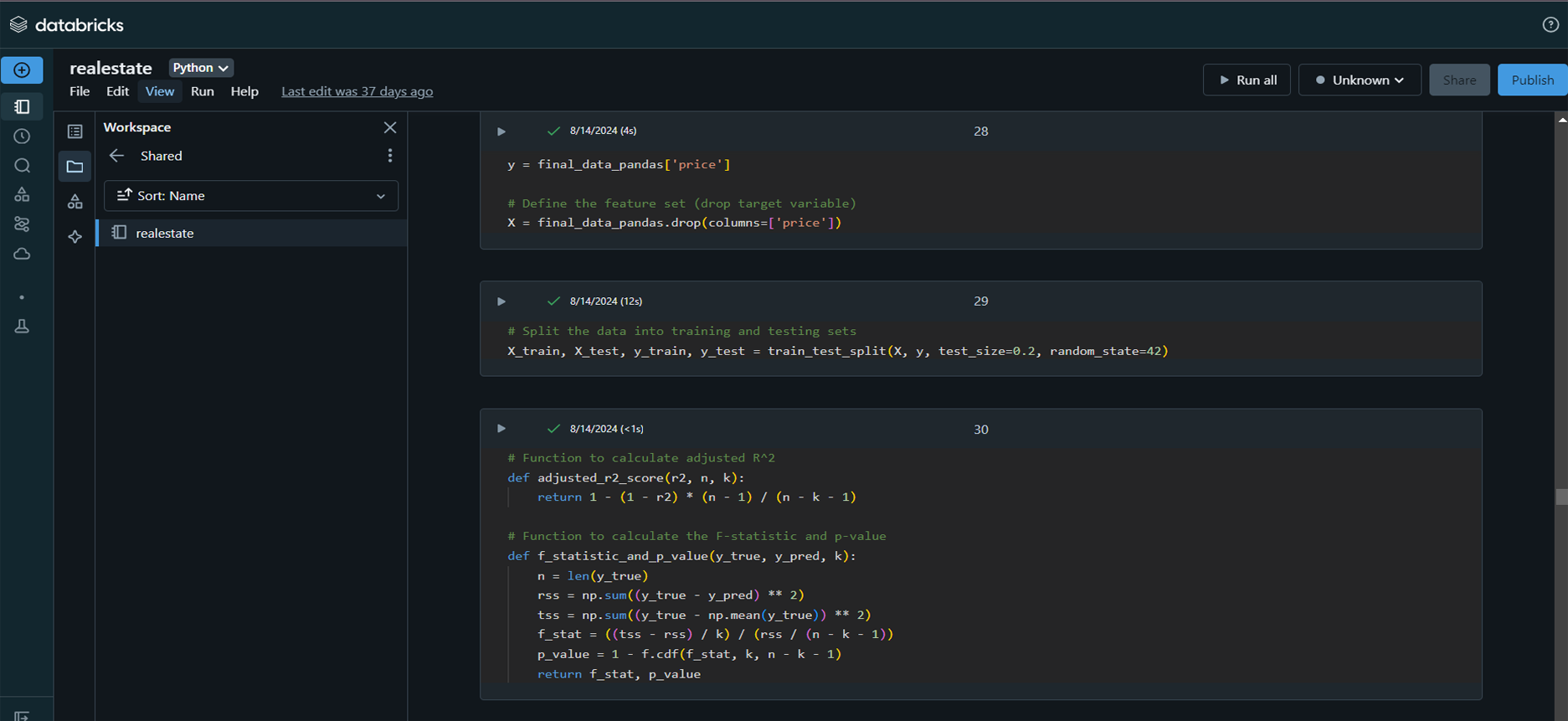
Model Implementation and Tuning:
Developed multiple regression models and optimized them
using Python and Databricks.
-
Model Evaluation and Selection:
Evaluated models using MSE, RMSE, R², Adjusted R², and
selected RandomForest Regression based on its superior
performance.
-
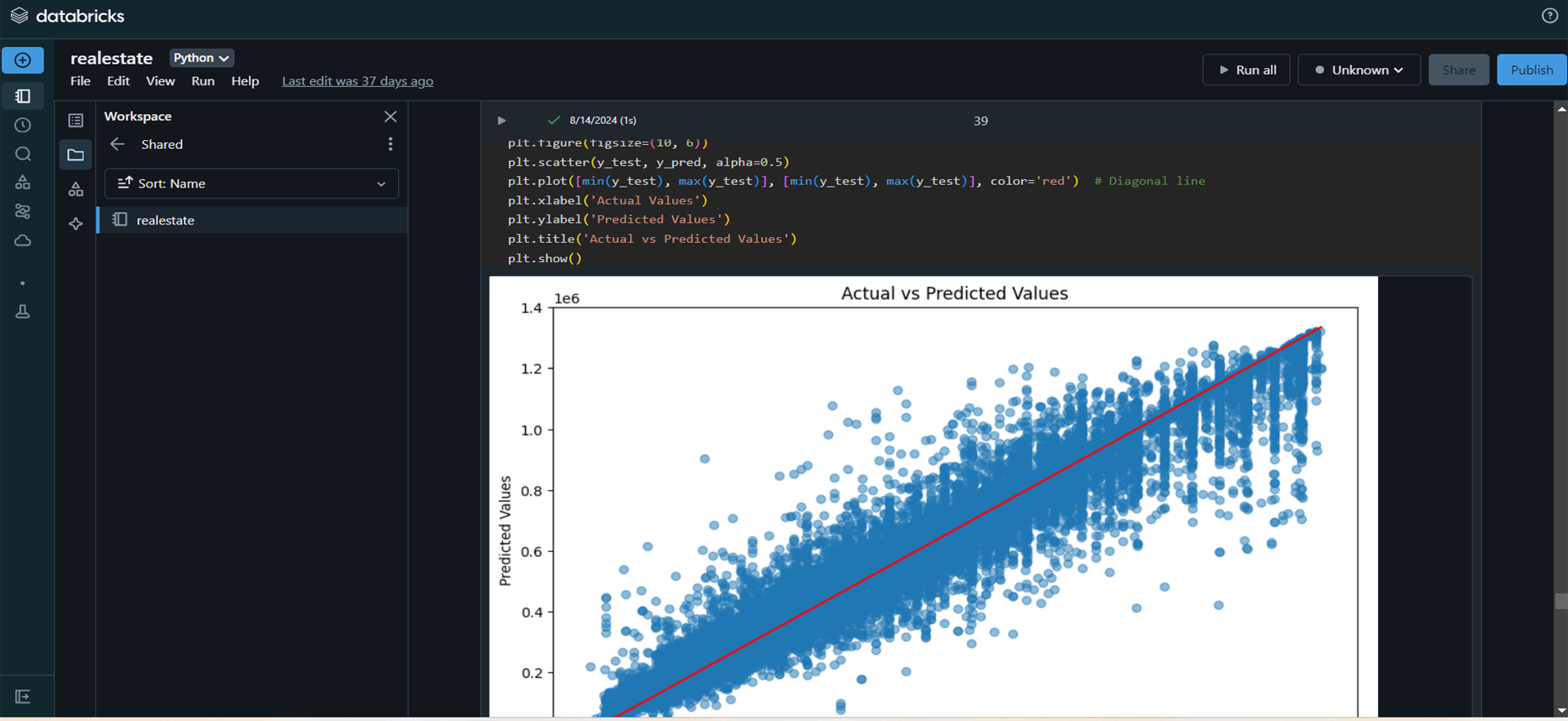
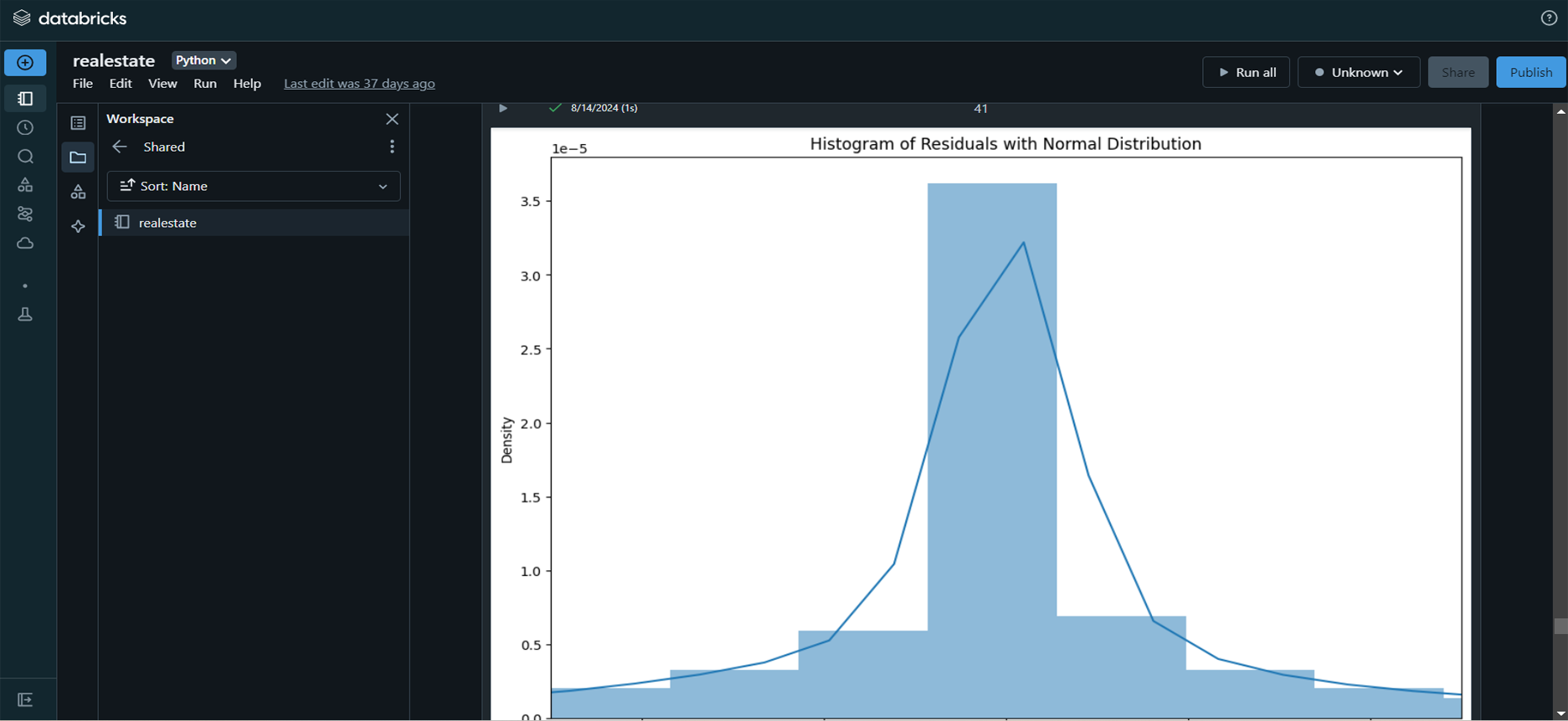
Visualization and Reporting: Created
various visualizations using Seaborn and Matplotlib to
assess model accuracy and presented key insights to
stakeholders.
-
Documentation: Documented the entire
project process, detailing model performance, data
cleaning techniques, and future recommendations.
GitHub Link: To see my project on GitHub
please click GitHub Repository button below
Project Summary:
This project involves analyzing home sales data using Apache
Spark's PySpark library to calculate average home prices
based on various criteria, such as the number of bedrooms,
bathrooms, and other features. Key aspects of the analysis
include executing queries to derive insights on pricing
trends, caching data for performance improvements, and
storing data in Parquet format for re-analysis. The project
emphasizes performance comparison between cached and
uncached data and demonstrates how Apache Spark can handle
large-scale data processing effectively. enhancing
decision-making based on historical stock data.
Read More
Technologies:
-
Apache Spark (PySpark): For large-scale
data processing and querying.
-
Spark SQL: Used to run SQL-like queries
on the data for analysis.
-
CSV Data: Dataset imported from an
external source for analysis.
-
Parquet Files: For efficient data
storage and retrieval during the analysis.
-
Python (time library): Used to measure
and compare query runtimes.
Highlighted Skills:
-
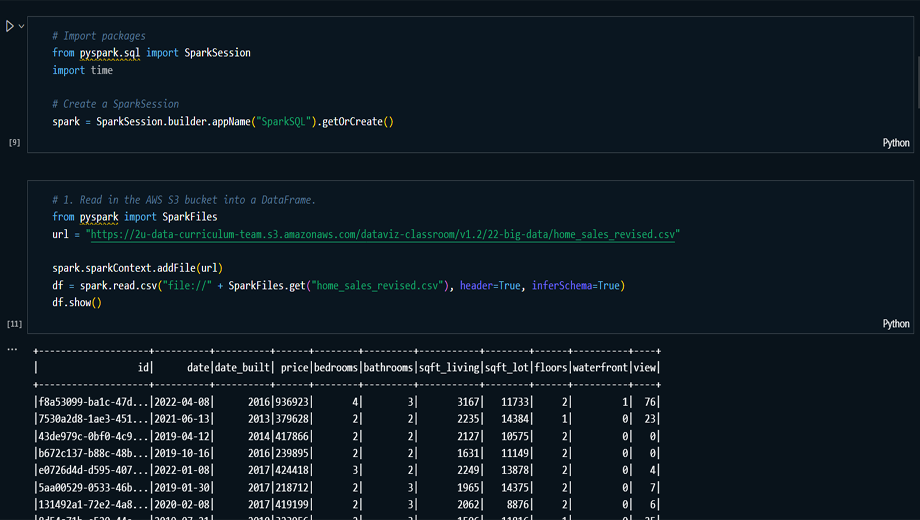
Data Ingestion and Setup: Initialized a
Spark session and imported necessary PySpark libraries
to ingest home sales data from a CSV file into a Spark
DataFrame.
-
Query Development: Designed and
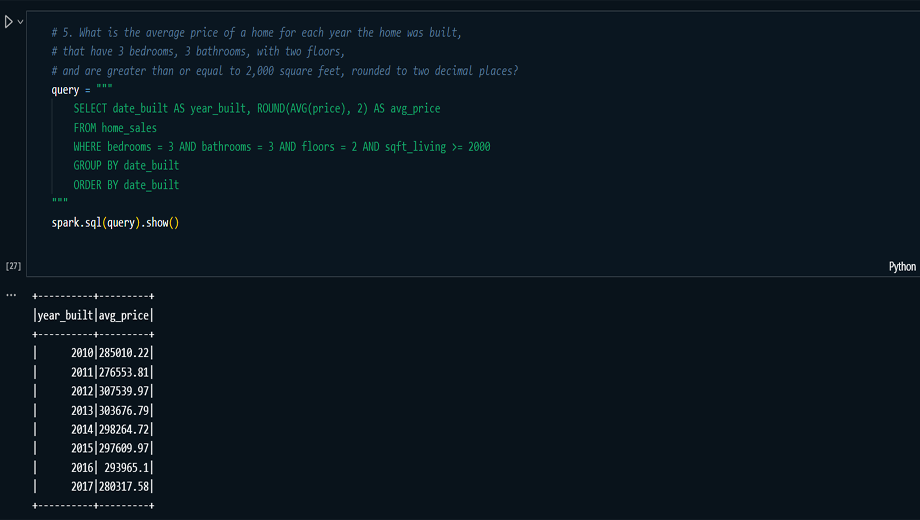
executed SQL queries in Spark SQL to extract insights,
such as the average price of homes with specific
features, and analyzed results based on year sold, year
built, and view ratings.
-
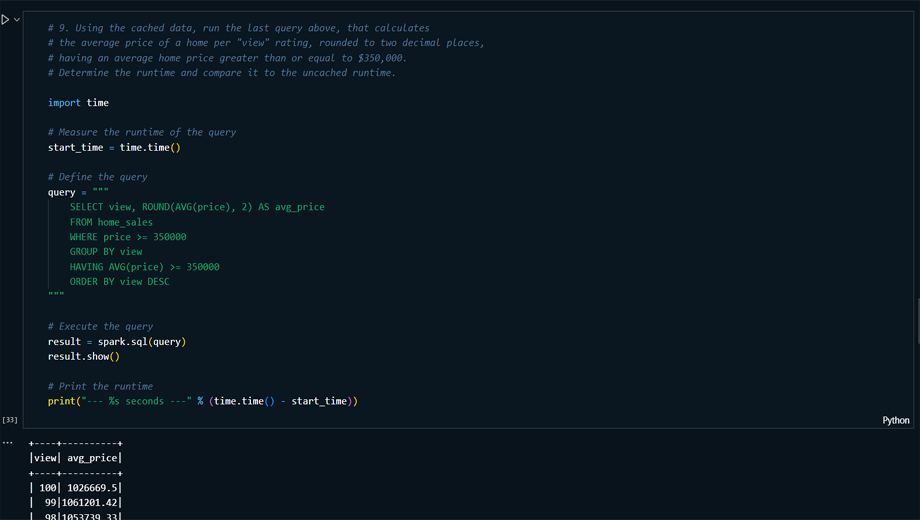
Performance Optimization: Improved
query performance by caching the home_sales table in
memory and comparing runtimes between cached and
uncached data.
-
Data Persistence: Persisted the
processed data by writing it to Parquet format,
partitioning the data by the year the home was built to
optimize future queries.
-
Performance Evaluation: Re-executed the
queries on Parquet data and compared the runtimes to
evaluate the effectiveness of using Parquet for storage
and performance improvement.
-
Documentation and Reporting: Documented
the steps taken for data ingestion, query execution,
caching, and performance evaluations, providing detailed
insights into the analysis process and the performance
benefits of caching and using Parquet files.
GitHub Link: To see my project on GitHub
please click GitHub Repository button below
Project Summary:
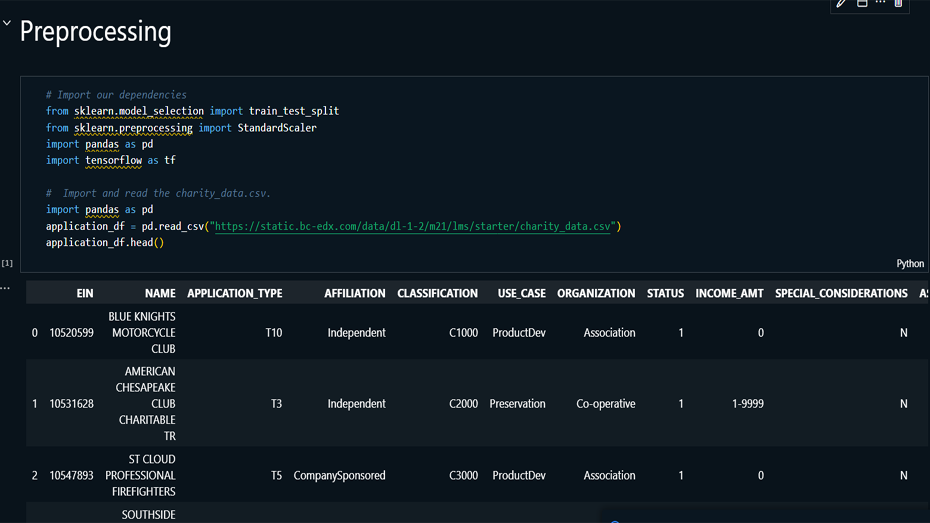
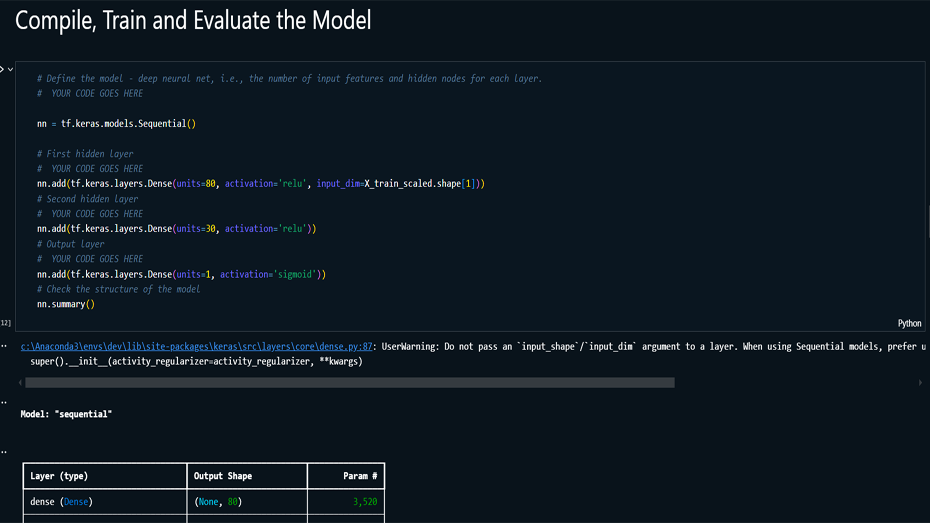
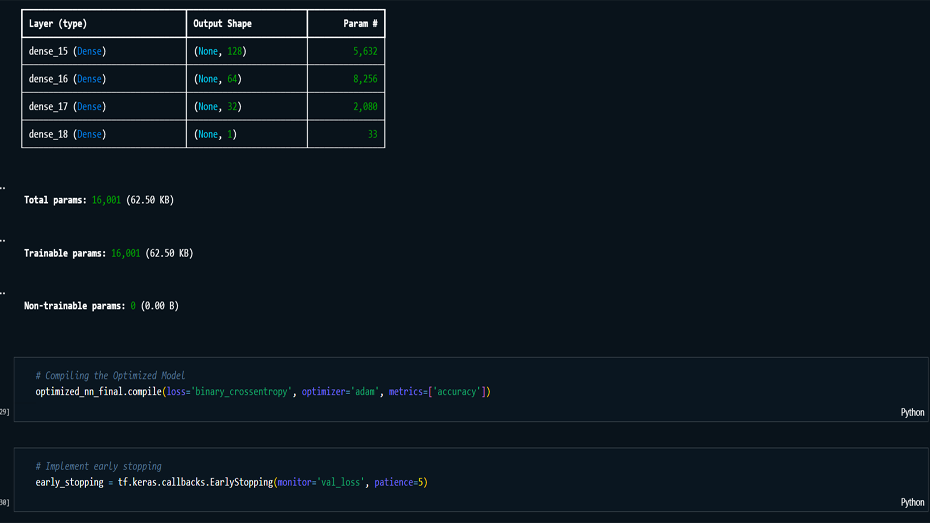
This project uses a neural network model to predict the
likelihood of charity applications being approved based on
historical data. Key features like application type,
affiliation, use case, and requested amounts were
preprocessed and fed into the model, which was trained and
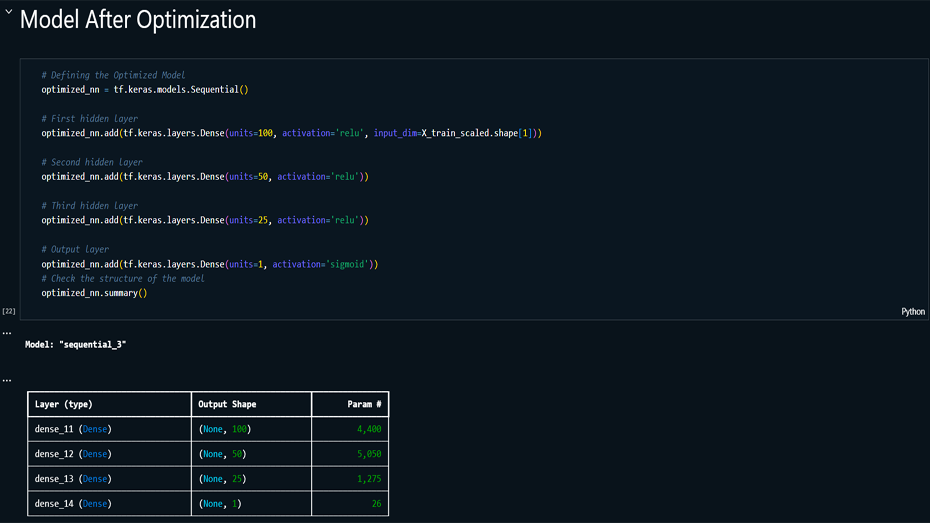
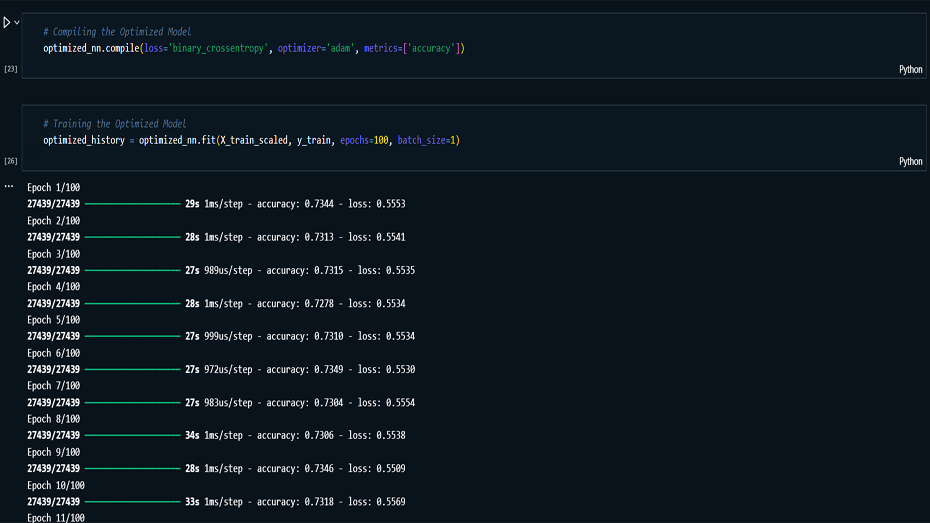
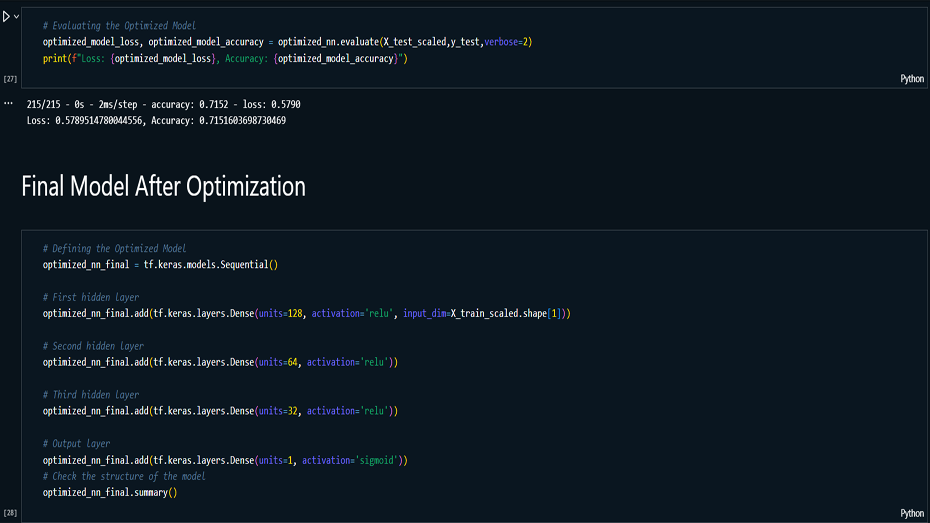
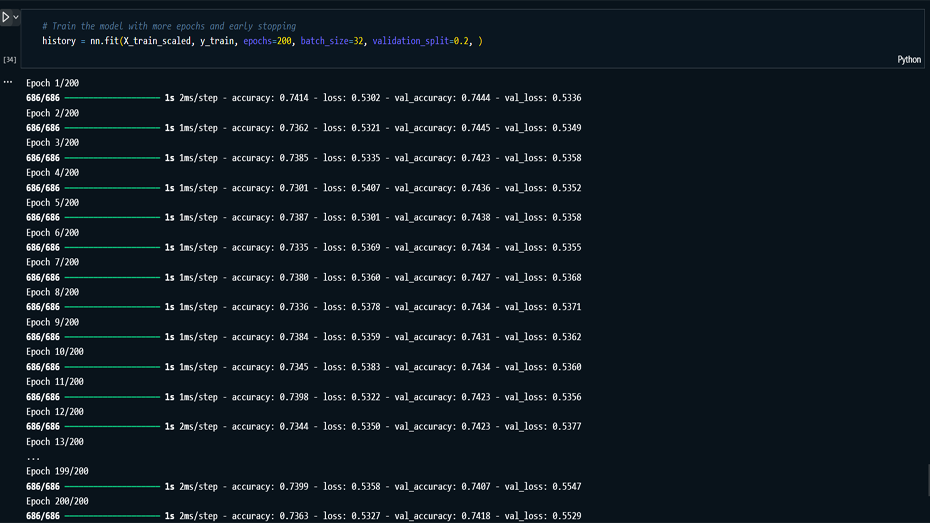
optimized through various iterations. The final model, with
multiple hidden layers and fine-tuned parameters, achieved a
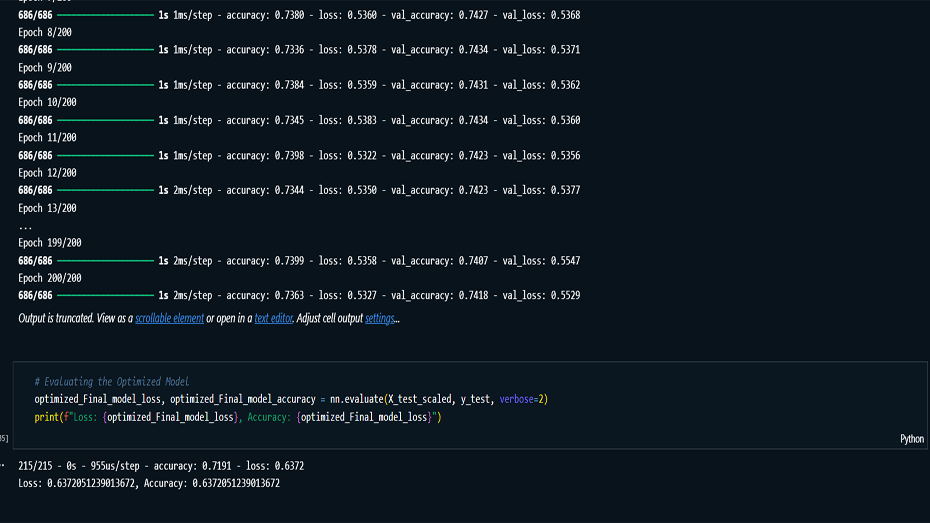
validation accuracy of 74.18%. Although the model shows
promise, further improvements are necessary to increase the
accuracy. This analysis provides valuable insights for
charities looking to improve their application success
rates.
Read More
Technologies:
-
Python: For model development and data
preprocessing.
-
TensorFlow & Keras: For building and
training the neural network.
-
pandas & NumPy: For data manipulation
and feature engineering.
-
scikit-learn: For preprocessing and
model evaluation.
-
Matplotlib & Seaborn: For data
visualization and performance plotting.
Highlighted Skills:
-
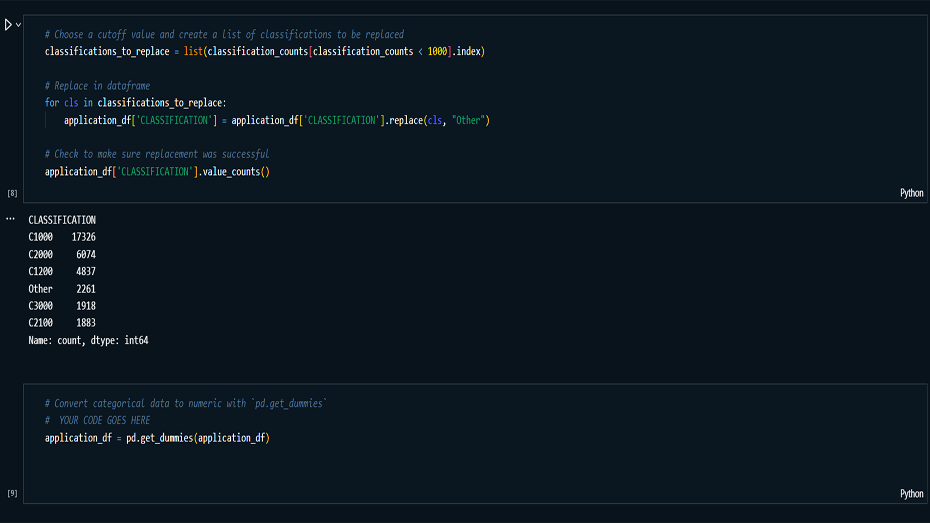
Data Preprocessing: Processed and
cleaned the charity application dataset by removing
irrelevant features (e.g., EIN, NAME) and transforming
categorical variables into numerical form.
-
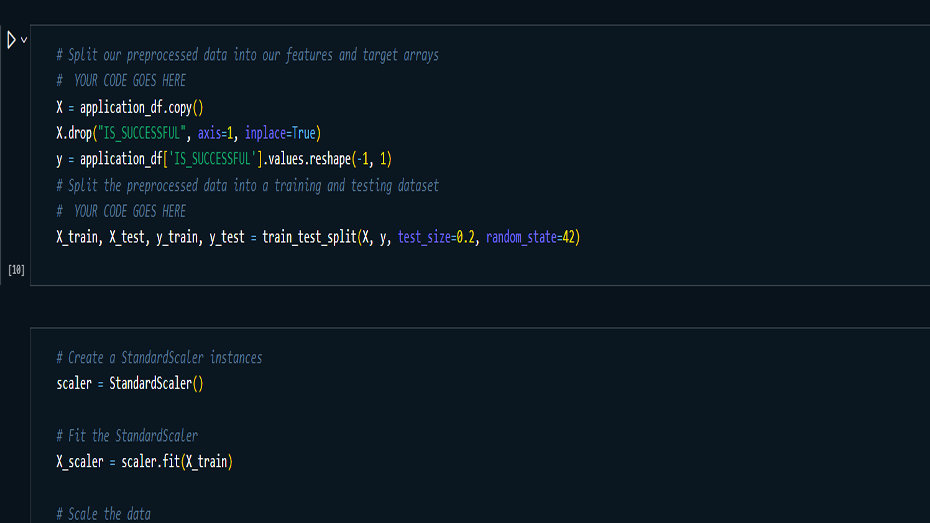
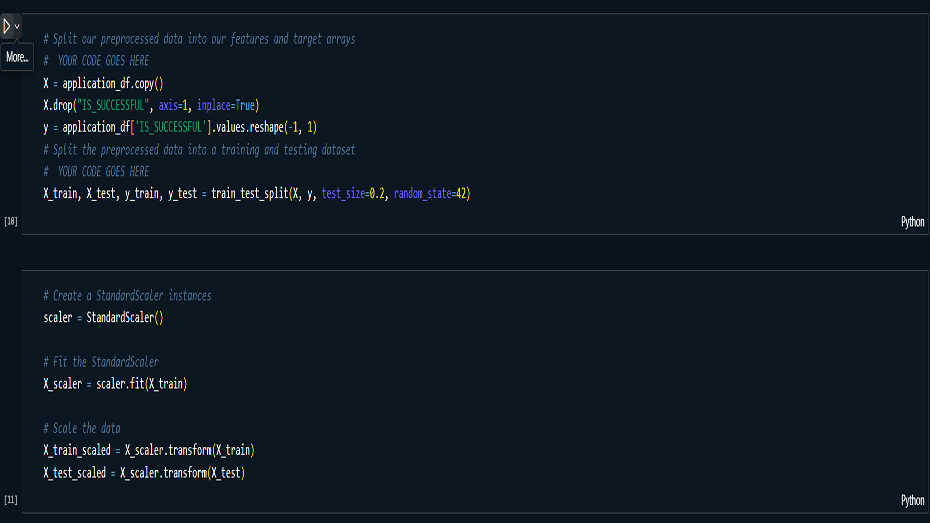
Model Building & Optimization: Built
and trained multiple iterations of neural networks,
optimizing hyperparameters such as the number of hidden
layers, neurons, activation functions, and batch size.
-
Performance Tuning: Introduced
techniques like early stopping and category grouping to
reduce overfitting and improve model accuracy.
-
Model Evaluation: Evaluated the final
model using metrics such as training and validation
accuracy, loss functions, and confusion matrices,
achieving a validation accuracy of 74.18%.
-
Visualization & Reporting: Created
plots to track model performance and highlighted key
insights on factors affecting the success of charity
applications.
GitHub Link: To see my project on GitHub
please click GitHub Repository button below
Project Summary:
This project showcases the development of a logistic
regression model for credit risk classification. With an
accuracy of 99.22%, the model performed well in identifying
both healthy and high-risk loans. Given the strong precision
and recall scores, especially for healthy loans, the model
is suitable for practical applications in credit risk
prediction. However, further model tuning or exploring more
complex algorithms could enhance performance in reducing
false positives and false negatives.
Read More
Technologies:
-
Python: Core programming language.
-
Scikit-Learn: Used for logistic
regression modeling, data splitting, and evaluation
metrics.
-
Pandas: For data manipulation and
exploration.
- NumPy: For numerical operations.
Highlighted Skills:
-
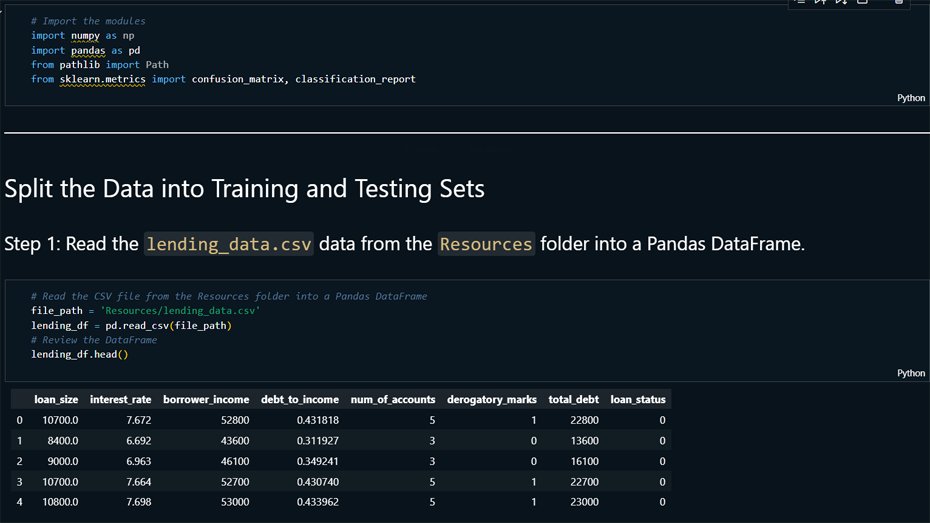
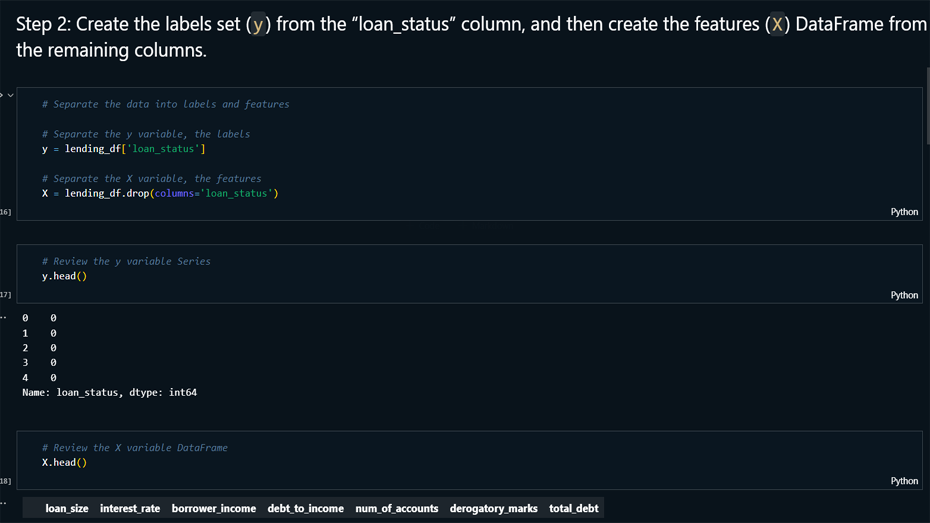
Data Preparation: Imported and reviewed
the loan dataset from a CSV file, and processed the data
by separating features (X) and labels (y) for model
training..
-
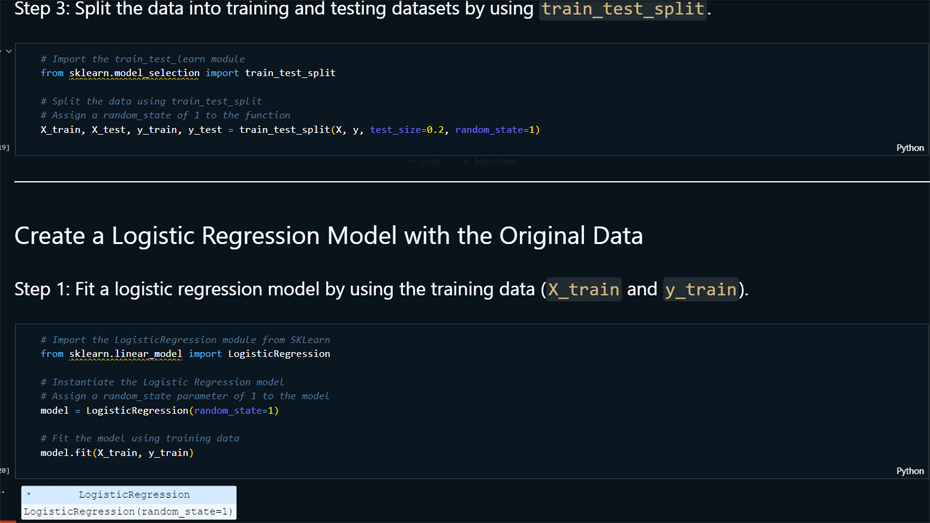
Model Training and Evaluation: Built a
logistic regression model using Scikit-Learn, split the
data into training/testing sets with train_test_split,
and evaluated the model using accuracy, precision,
recall, F1-score, and a confusion matrix.
-
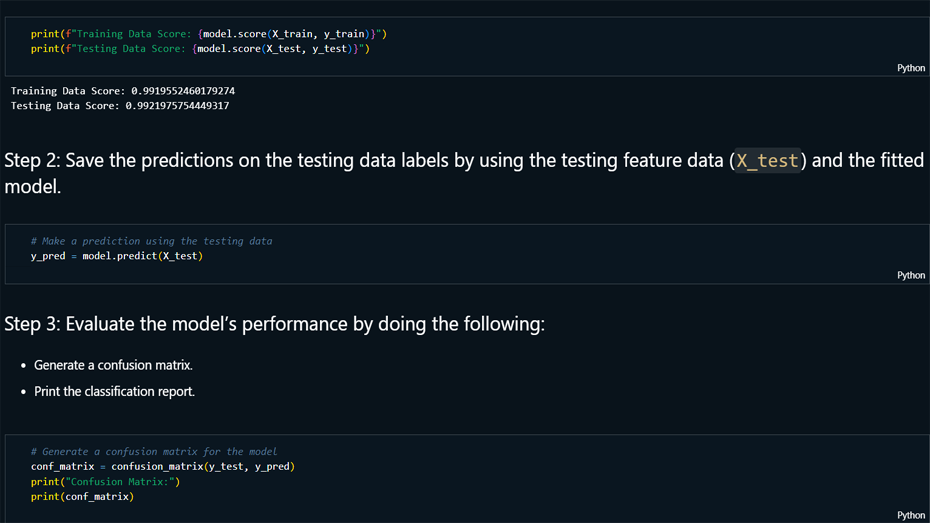
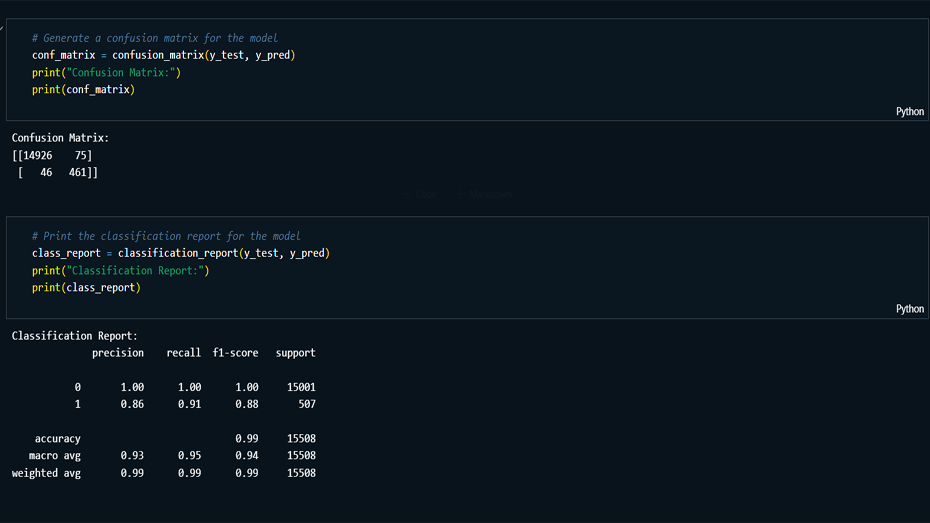
Results Analysis: Achieved an overall
accuracy of 99.22%, with Class 0 showing perfect
precision, recall, and F1-scores of 1.00, and Class 1
reaching a precision of 0.86, recall of 0.91, and an
F1-score of 0.88.
-
Performance Reporting: Documented and
analyzed key performance metrics, summarizing confusion
matrix results, and recommended improvements to reduce
false positives/negatives.
GitHub Link: To see my project on GitHub
please click GitHub Repository button below
Project Summary:
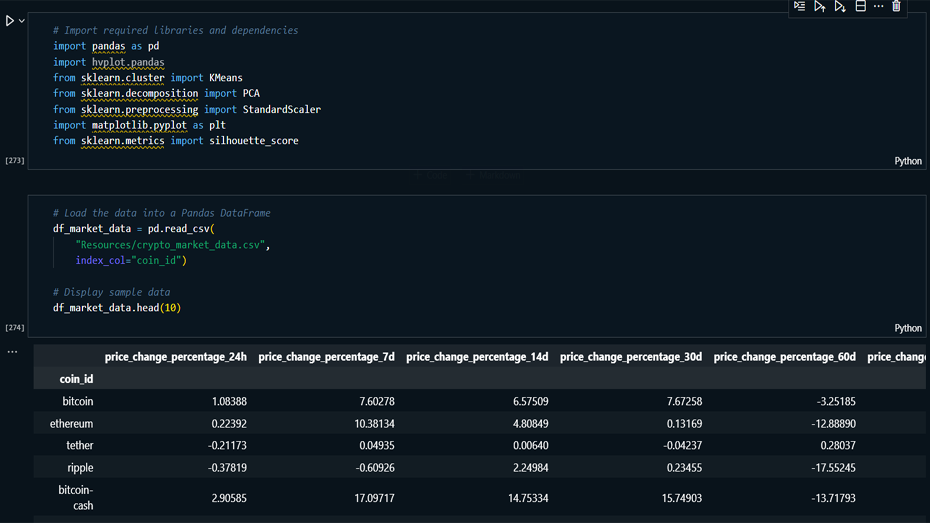
This project focuses on clustering cryptocurrencies based on
their market performance data. Using K-Means clustering and
Principal Component Analysis (PCA), the goal is to identify
patterns and group similar cryptocurrencies. By reducing
dimensionality with PCA, I further optimized the clustering
process while retaining a high amount of variance from the
original dataset.
Read More
Technologies:
-
Python: For scripting and analysis.
-
pandas: For data manipulation and
preprocessing.
-
scikit-learn: For K-Means clustering
and PCA.
-
Hvploat & Matplotlib: For data
visualization.
-
StandardScaler: For data normalization.
-
Jupyter Notebook: For interactive
analysis and reporting.
Highlighted Skills:
-
Data Preprocessing Imported and
explored cryptocurrency market data, cleaned and
normalized it using StandardScaler.
-
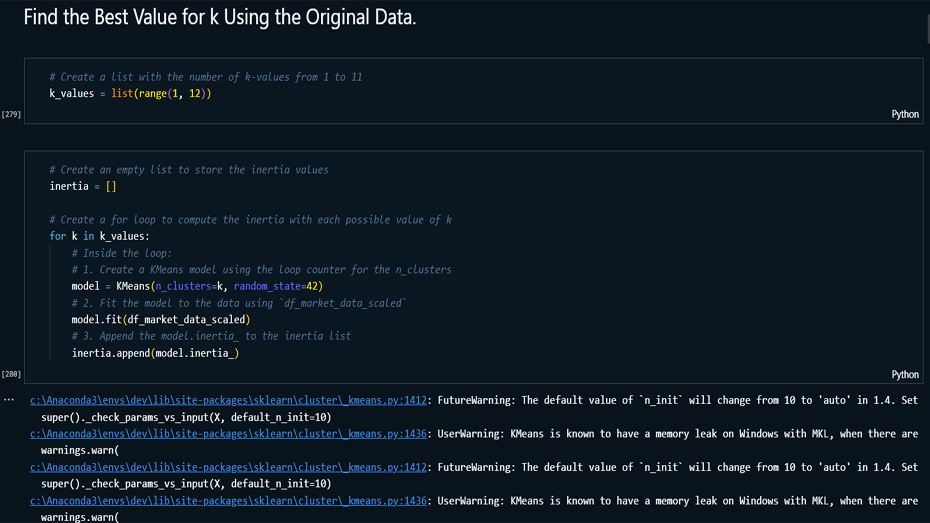
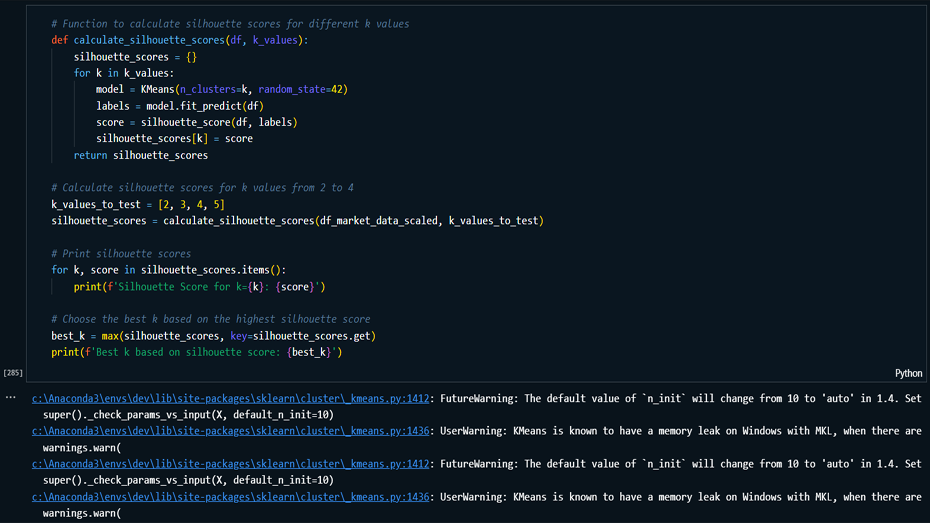
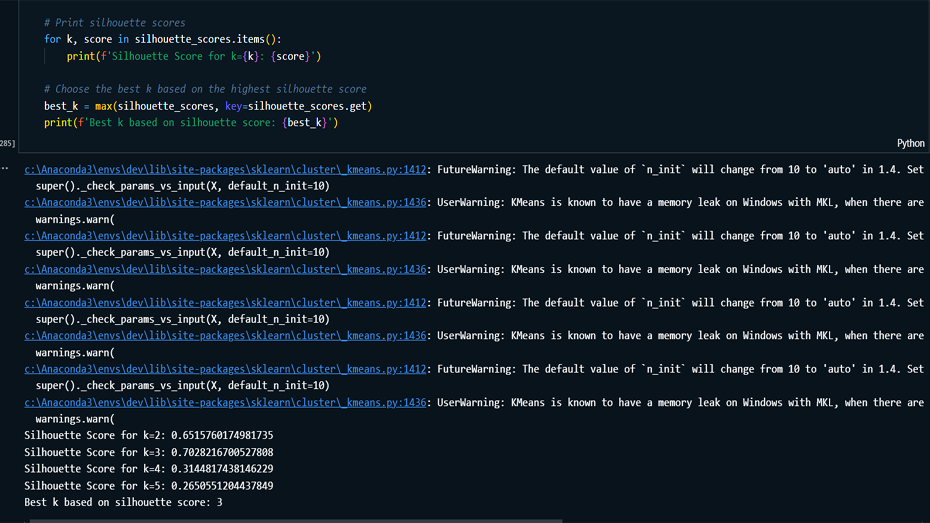
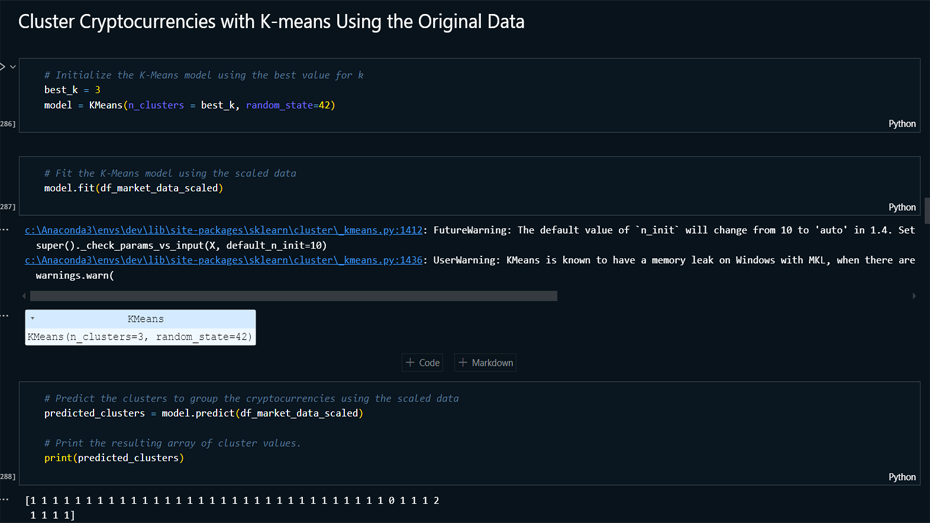
Model Building: Implemented K-Means
clustering on the original and PCA-transformed data,
determining the optimal number of clusters using the
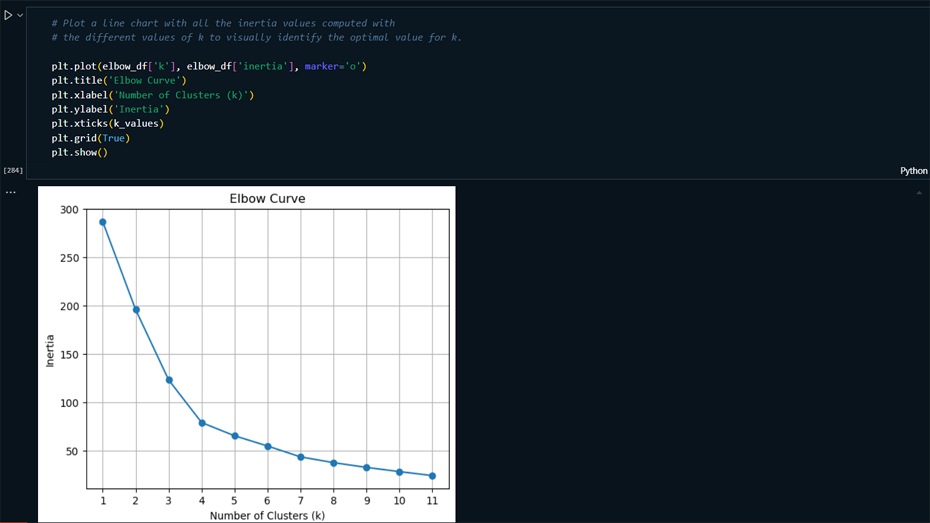
Elbow method.
-
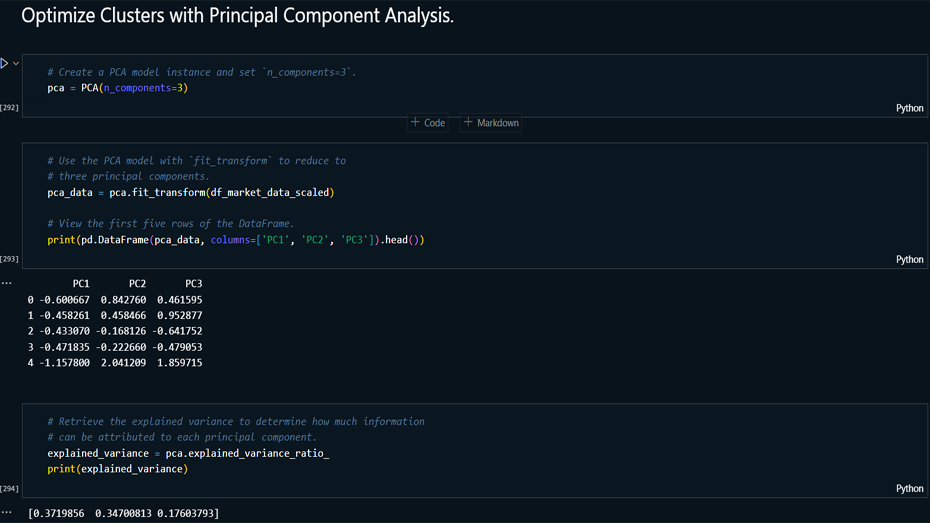
Dimensionality Reduction: Applied PCA
to reduce the dataset to three principal components
while retaining 89.5% of the original variance.
-
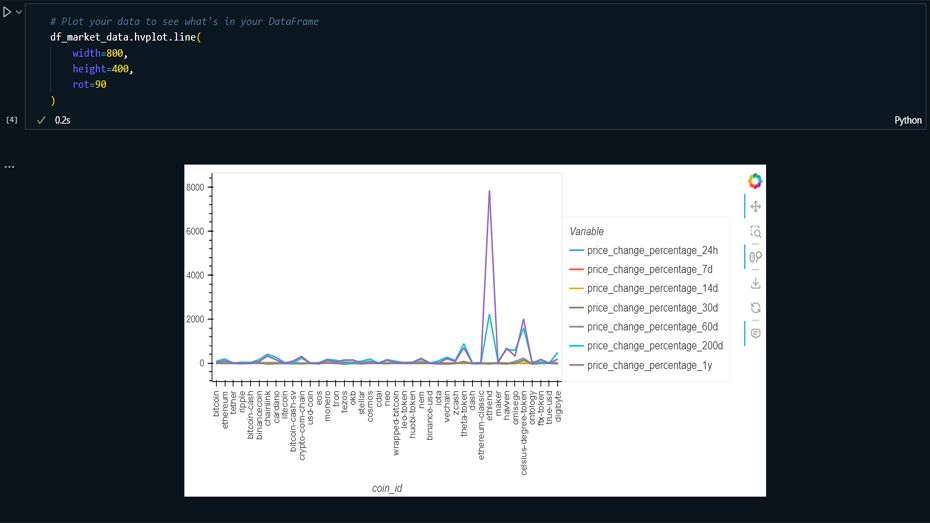
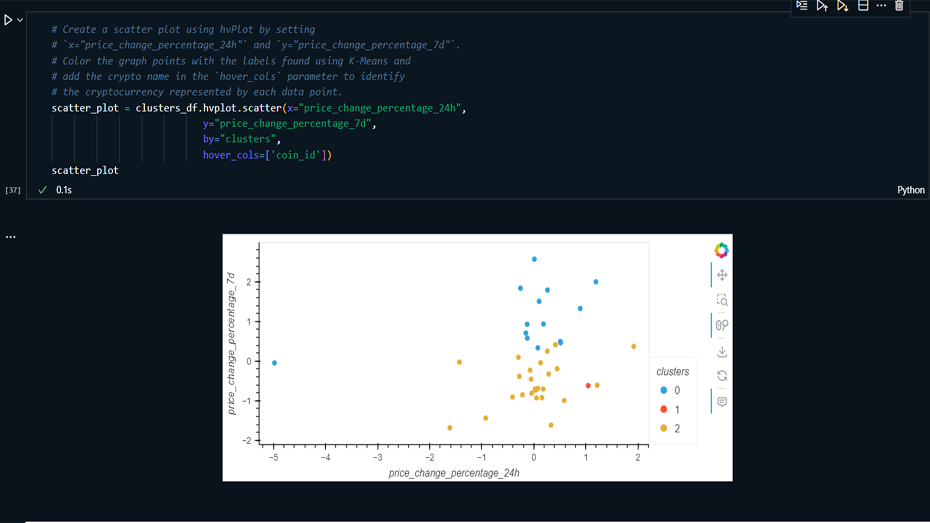
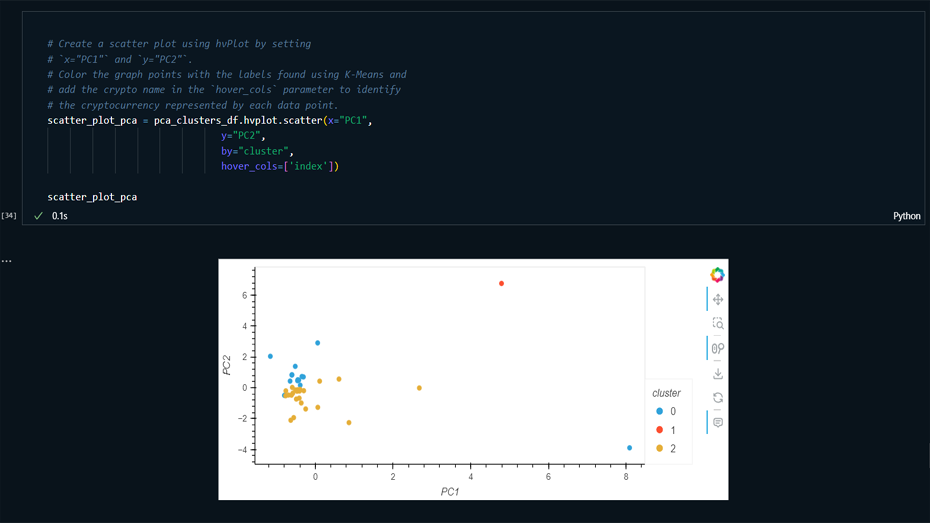
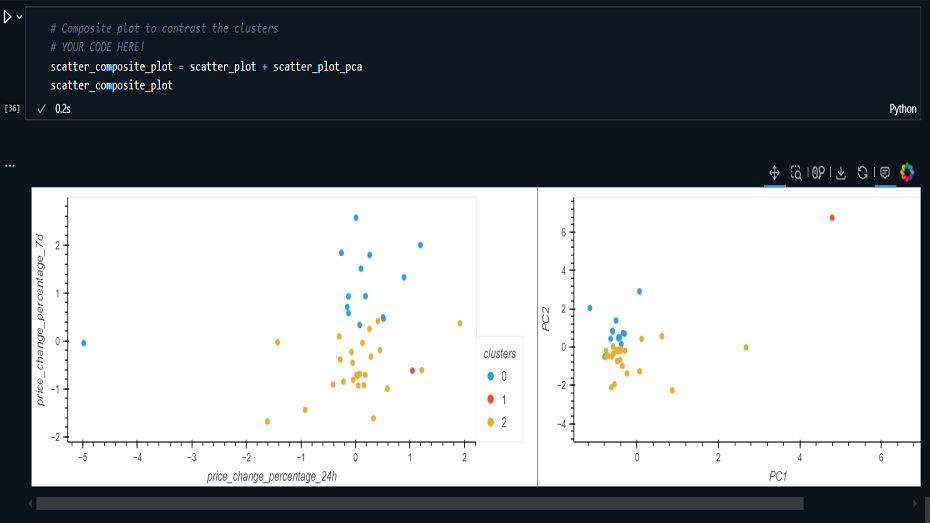
Visualization: Created Elbow curves and
scatter plots to visualize clustering results and
compare original data with PCA-reduced data.
-
Analysis & Reporting: Analyzed and
interpreted the clustering results, providing insights
into the behavior of cryptocurrency clusters and the
impact of dimensionality reduction.
GitHub Link: To see my project on GitHub
please click GitHub Repository button below